LeetCode:最长公共前缀
2020-06-15
4 min read
题目
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
说明: 所有输入只包含小写字母 a-z 。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/longest-common-prefix
解法
方法1和方法2比较常规,我自己解题的时候用的方法2。方法3利用字符串排序,非常巧妙。方法4是字典树,直觉上可以,但是我对字典树不是很熟悉。
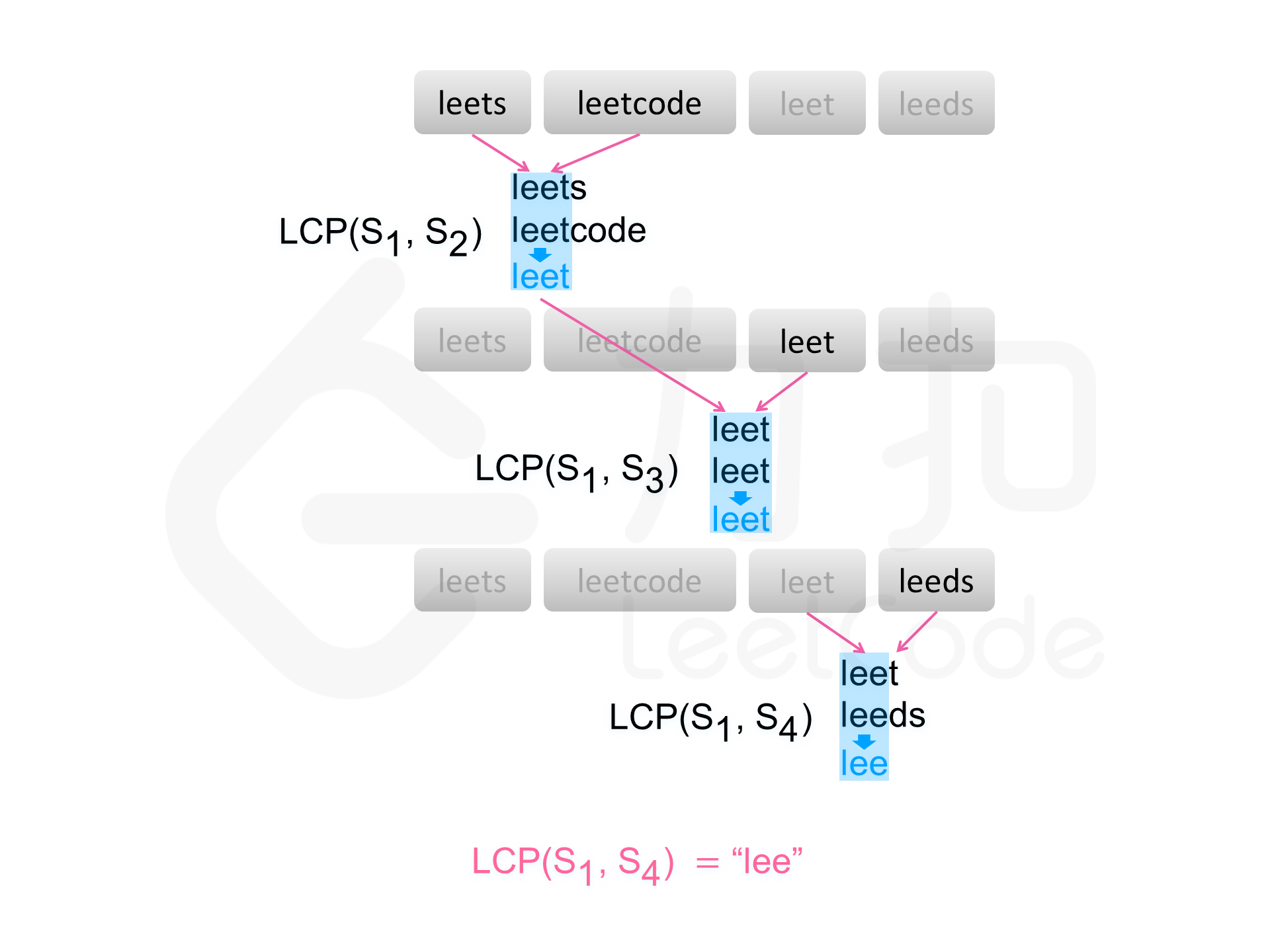
横向扫描
依次遍历字符串数组中的每个字符串,对于每个遍历到的字符串,更新最长公共前缀,当遍历完所有的字符串以后,即可得到字符串数组中的最长公共前缀。
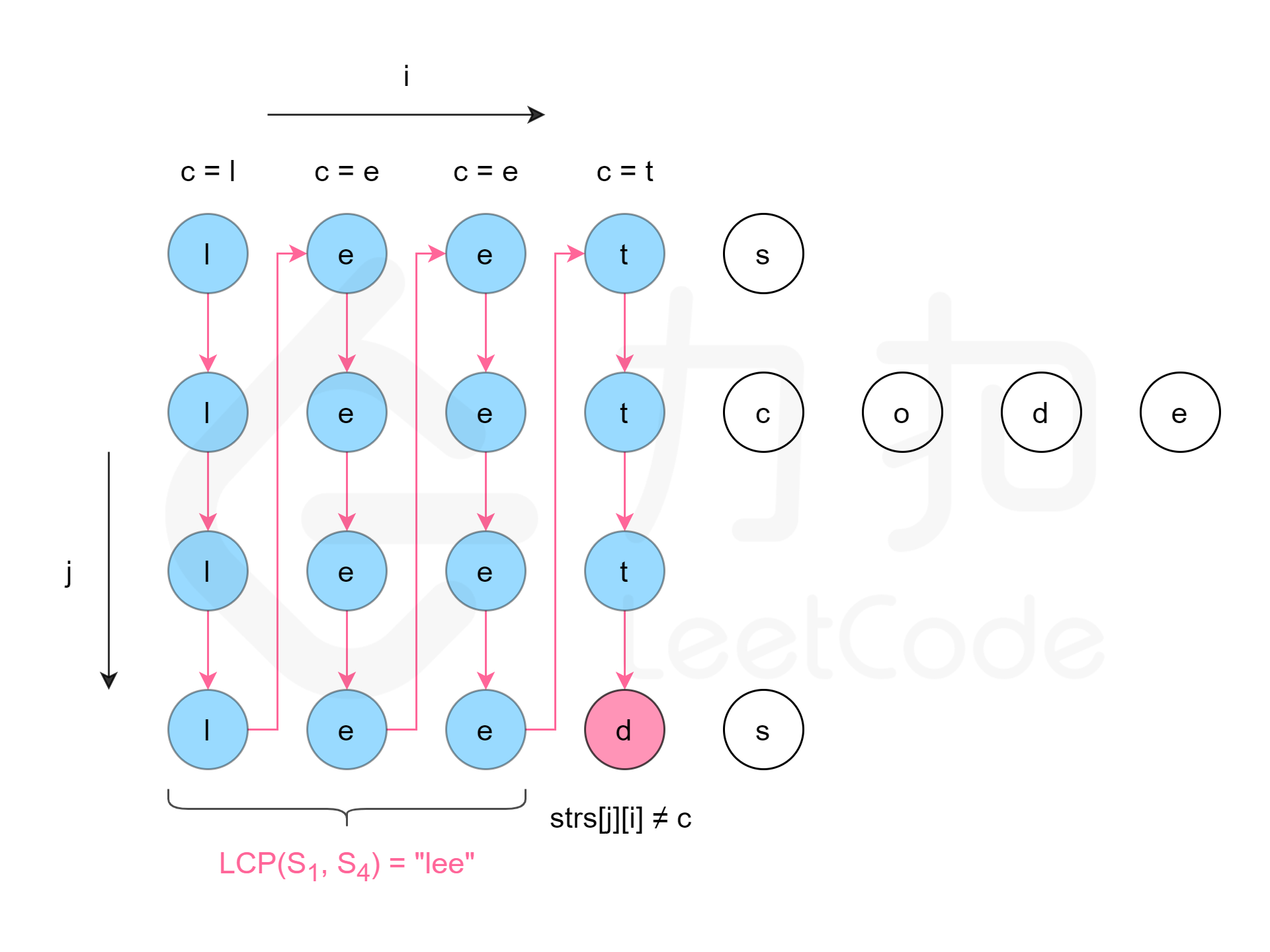
纵向扫描
纵向扫描时,从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀,当前列之前的部分为最长公共前缀。
这种方法和我想的一致,贴一下我的代码:
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
cp = ""
if not strs:
return cp
min_str_len = min([len(s) for s in strs])
strs_num = len(strs)
for i in range(min_str_len):
temp = strs[0][i]
same = True
for j in range(strs_num):
if strs[j][i] != temp:
same =False
break
if same:
cp += temp
else:
return cp
return cp
在题解中还看到一种使用zip函数的便捷写法:
class Solution(object):
def longestCommonPrefix(self, strs):
ans = ''
for i in zip(*strs):
if len(set(i)) == 1:
ans += i[0]
else:
break
return ans
利用python的zip函数,把str看成list然后把输入看成二维数组,左对齐纵向压缩,然后把每项利用集合去重,之后遍历list中找到元素长度大于1之前的就是公共前缀。
字符串排序
利用python的max()和min(),在python里字符串是可以比较的,按照ascII值排,举例abb, aba,abac,最大为abb,最小为aba。所以只需要比较最大最小的公共前缀就是整个数组的公共前缀。
def longestCommonPrefix(self, strs):
if not strs: return ""
s1 = min(strs)
s2 = max(strs)
for i,x in enumerate(s1):
if x != s2[i]:
return s2[:i]
return s1
字典树
暂时不明白,后续理解一下。
from collections import defaultdict
from functools import reduce
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:return ""
trieNode = lambda:defaultdict(trieNode)
class Trie:
def __init__(self):
self.trie = trieNode()
def insert(self,word):
reduce(dict.__getitem__,word,self.trie)['END'] = True
def search(self,word):
reduce(lambda d,k:d[k] if k in d else trieNode(),word,self.trie).get('END',False)
def startsWith(self,word):
return len(reduce(lambda d,k:d[k] if k in d else trieNode(),word,self.trie)) > 0
def longestCommonPrefix(self):
commonPrefixes = ""
starts = self.trie
while ('END' not in starts) and len(starts) == 1:
append = list(starts.keys())[0]
starts = starts.get(append)
commonPrefixes += append
return commonPrefixes
trie = Trie()
for word in strs:
trie.insert(word)
return trie.longestCommonPrefix()